
RESEARCH
Peer-Reviewd Publications
The Agricultural Productivity Gap: Informality Matters
(with Bharat Ramaswami )
[Journal of Development Economics (Vol 178, January 2026).]
[Media Coverage by Ideas for India.]
(with Bharat Ramaswami )
[Journal of Development Economics (Vol 178, January 2026).]
[Media Coverage by Ideas for India.]
1 / 3

Productivity Gap --- Informality
2 / 3

Informed View of Productivity Gap
3 / 3
Policy Implication
We find that the primary dualism in development is between the formal non-farm sector and the informal sector including agriculture. Non-parametric econometric techniques are used for analysis.
[Published Version] [Working Paper Version]
Abstract
The measured agricultural productivity gap (APG) in developing countries typically compares agriculture with the entire non-farm economy, implicitly treating the latter as homogeneous. In developing countries, most non-farm employment is informal, concentrated in small, unregistered enterprises with low productivity. This paper compares the productivity of agriculture to the informal and formal non-farm sectors in India. Using Indian sectoral data from the India KLEMS database linked with nationally representative labor surveys, we decompose the non-farm economy into formal and informal segments and adjust productivity measures for differences in hours worked, human capital, and labor's share of value-added. We find that the APG is almost entirely driven by the small formal non-farm sector. The gap with the informal sector is negligible. Between 63 and 75 % of non-farm workers are in informal employment dominated industries that are not more productive than agriculture. These results reframe the APG as a formal–informal divide.
Working Papers
Kernel Three Pass Regression Filter
(with Daanish Padha)
[Award winner at The World Congress of the Econometrics Society, Seoul, 2025]
[Accepted for Presentation in The 2024 California Econometrics Conference]
[Accepted for Presentation in European Winter Meeting of the Econometric Society (EWMES) 2024]
[Accepted for Presentation in 19th Annual Conference on Economic Growth and Development at Indian Statistical Institute]
[Accepted for Presentation in The 34th Annual Midwest Econometrics Group Conference, USA]
(with Daanish Padha)
[Award winner at The World Congress of the Econometrics Society, Seoul, 2025]
[Accepted for Presentation in The 2024 California Econometrics Conference]
[Accepted for Presentation in European Winter Meeting of the Econometric Society (EWMES) 2024]
[Accepted for Presentation in 19th Annual Conference on Economic Growth and Development at Indian Statistical Institute]
[Accepted for Presentation in The 34th Annual Midwest Econometrics Group Conference, USA]
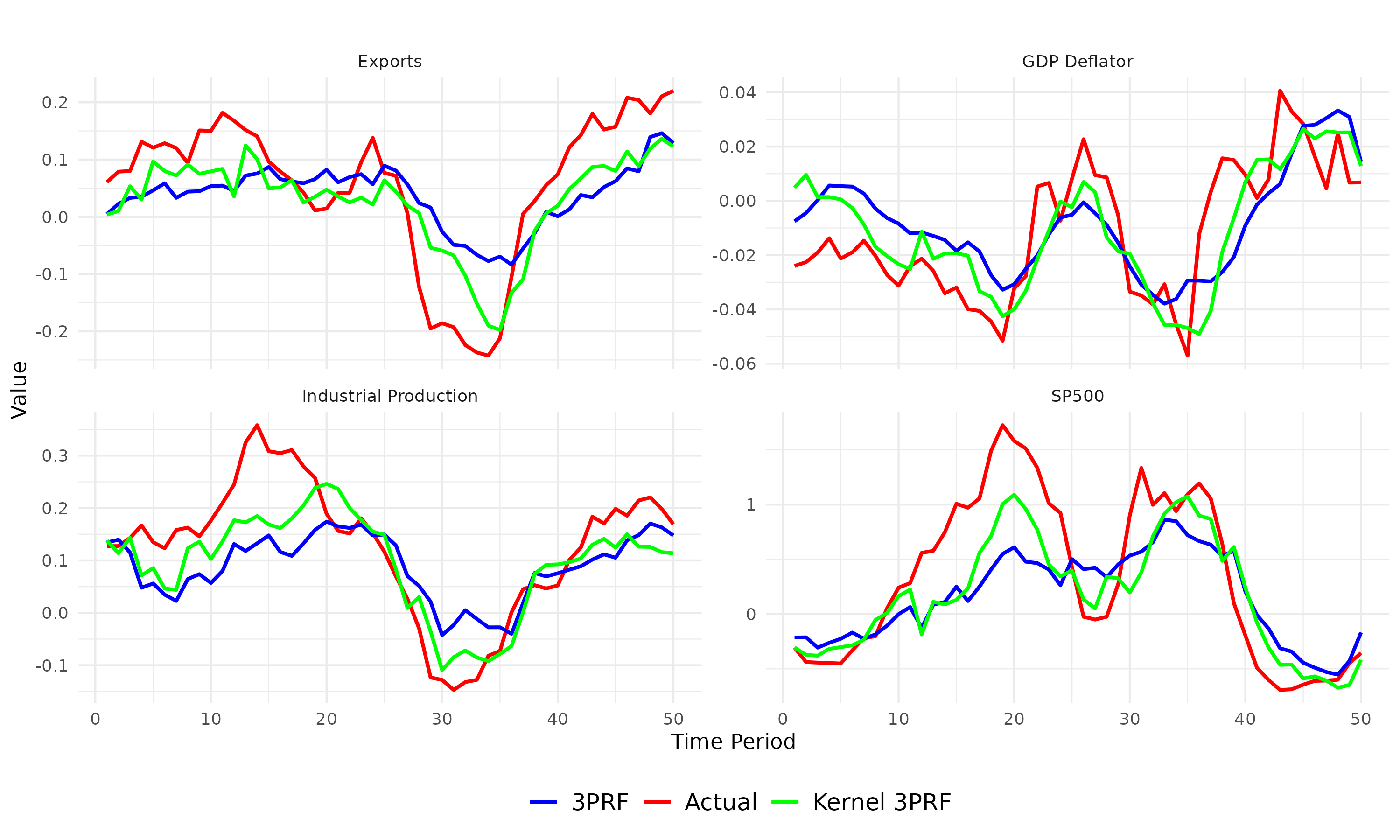
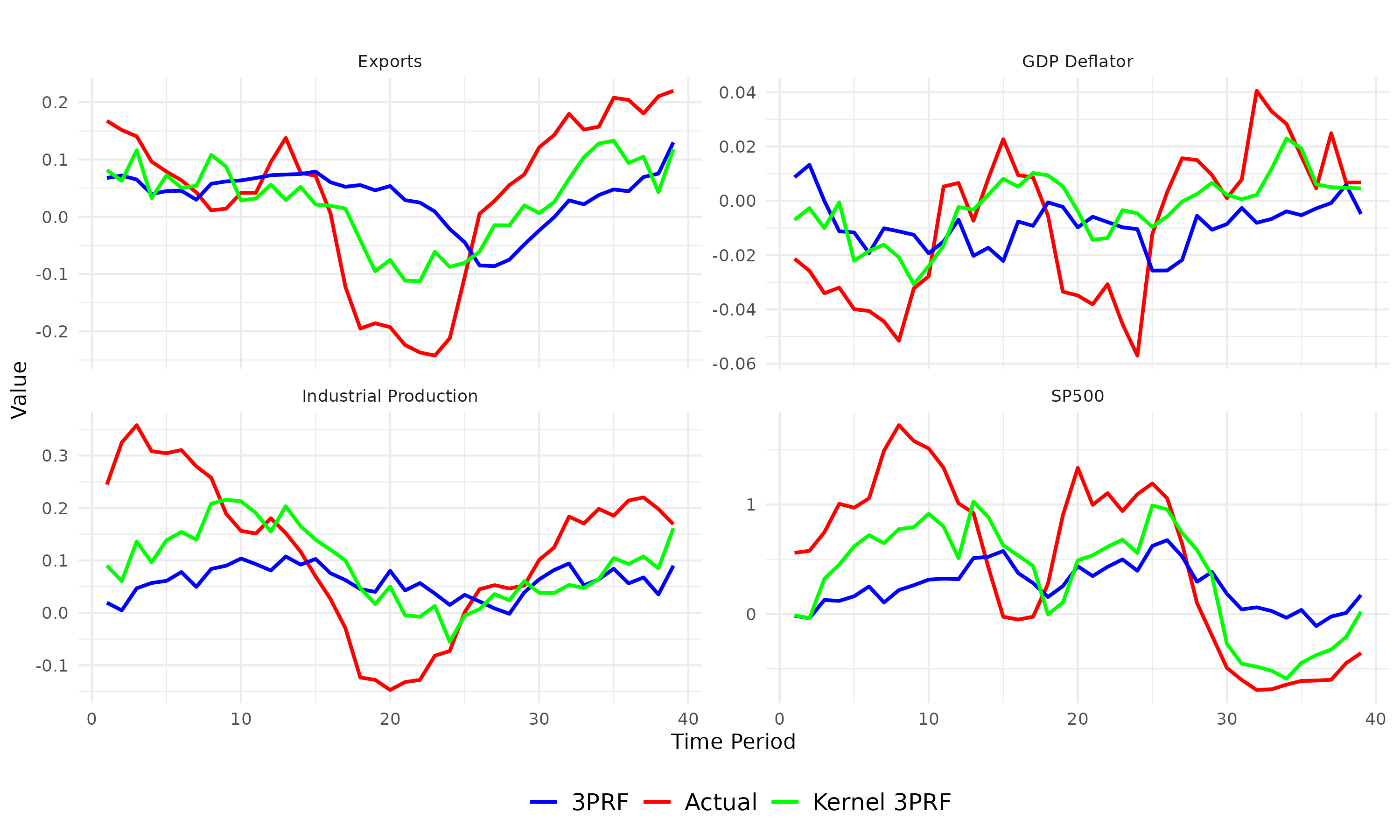
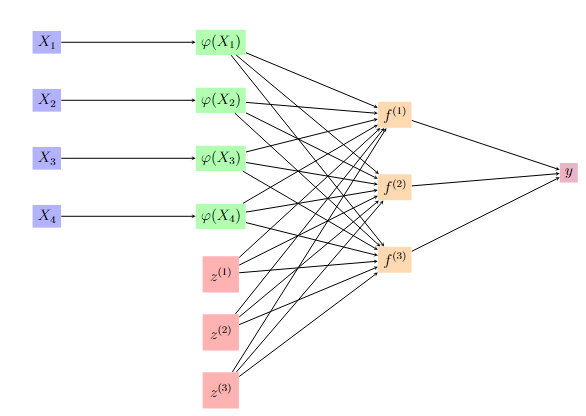
We propose a novel supervised and non-linear method of forecasting a single time series using a high-dimensional set of predictors. The method is computationally efficient and demonstrates strong empirical performance, particularly over longer forecast horizons.
[Paper] [Poster]
Abstract
We forecast a single time series using a high-dimensional set of predictors. When predictors share common underlying dynamics, a latent factor model estimated by the Principal Component method effectively characterizes their comovements. These latent factors succinctly summarize the data and aid in prediction, mitigating the curse of dimensionality. However, two significant drawbacks arise: (1) not all factors may be relevant, and utilizing all of them in constructing forecasts leads to inefficiency, and (2) typical models assume a linear dependence of the target on the set of predictors, which limits accuracy. We address these issues through a novel method: Kernel Three-Pass Regression Filter. This method extends a supervised forecasting technique, the Three-Pass Regression Filter, to exclude irrelevant information and operate within an enhanced framework capable of handling nonlinear dependencies. Our method is computationally efficient and demonstrates strong empirical performance, particularly over longer forecast horizons.
Sufficient Instruments Filter
[Accepted for Presentation in The 35th Annual Midwest Econometrics Group Conference, USA]
[Accepted for Presentation in The 2025 California Econometrics Conference]
[Invited talks at: Southern Illinois University Carbondale, Gettysburg College Pennsylvania, University of Guelph Canada]
[Invited talks at: Indian Statistical Institute Delhi and Indian Institute of Technology Delhi]
[Accepted for Presentation in The 35th Annual Midwest Econometrics Group Conference, USA]
[Accepted for Presentation in The 2025 California Econometrics Conference]
[Invited talks at: Southern Illinois University Carbondale, Gettysburg College Pennsylvania, University of Guelph Canada]
[Invited talks at: Indian Statistical Institute Delhi and Indian Institute of Technology Delhi]
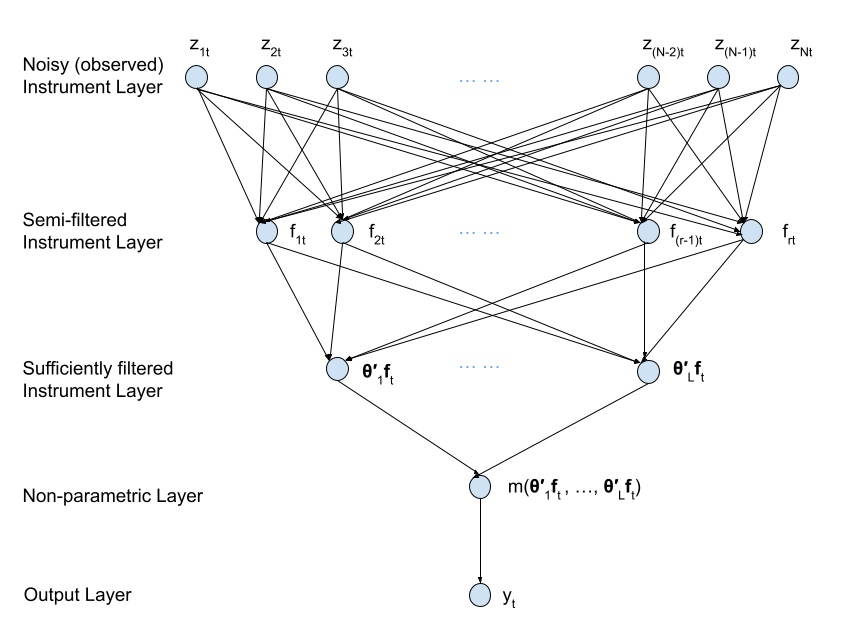
This paper introduces a novel procedure to filter out sufficient information from many instruments for the estimation of parameters in regression models with endogenous regressors. This method allows correlated and even invalid instruments. This technique draws its merit from the ability to incorporate supervision, the flexibility to accommodate non-linearity, and the capability for sufficient dimension reduction.
[Paper]
Abstract
This paper introduces a novel five-layered deep learning-based tractable procedure to filter out sufficient information from many instruments for estimating parameters in regression models with endogenous regressors. The method draws its merit from three key properties: the ability to incorporate supervision, the flexibility to accommodate non-linearity, and the capability for sufficient dimension reduction. This method is consistent and asymptotically normal when many instruments are correlated. Simulation exercises show that this method consistently achieves lower bias and root mean squared error compared to competing benchmarks, across many specifications. Two real-world applications in industrial organizations(IO) and finance are considered, yielding meaningful insights into causal relationships. The method remains robust when the number of instruments exceeds the sample size, and performs well with weak and even invalid observed instruments, as long as there exists at least one linear combination of common factors among the observed instruments that serves as a valid instrument.
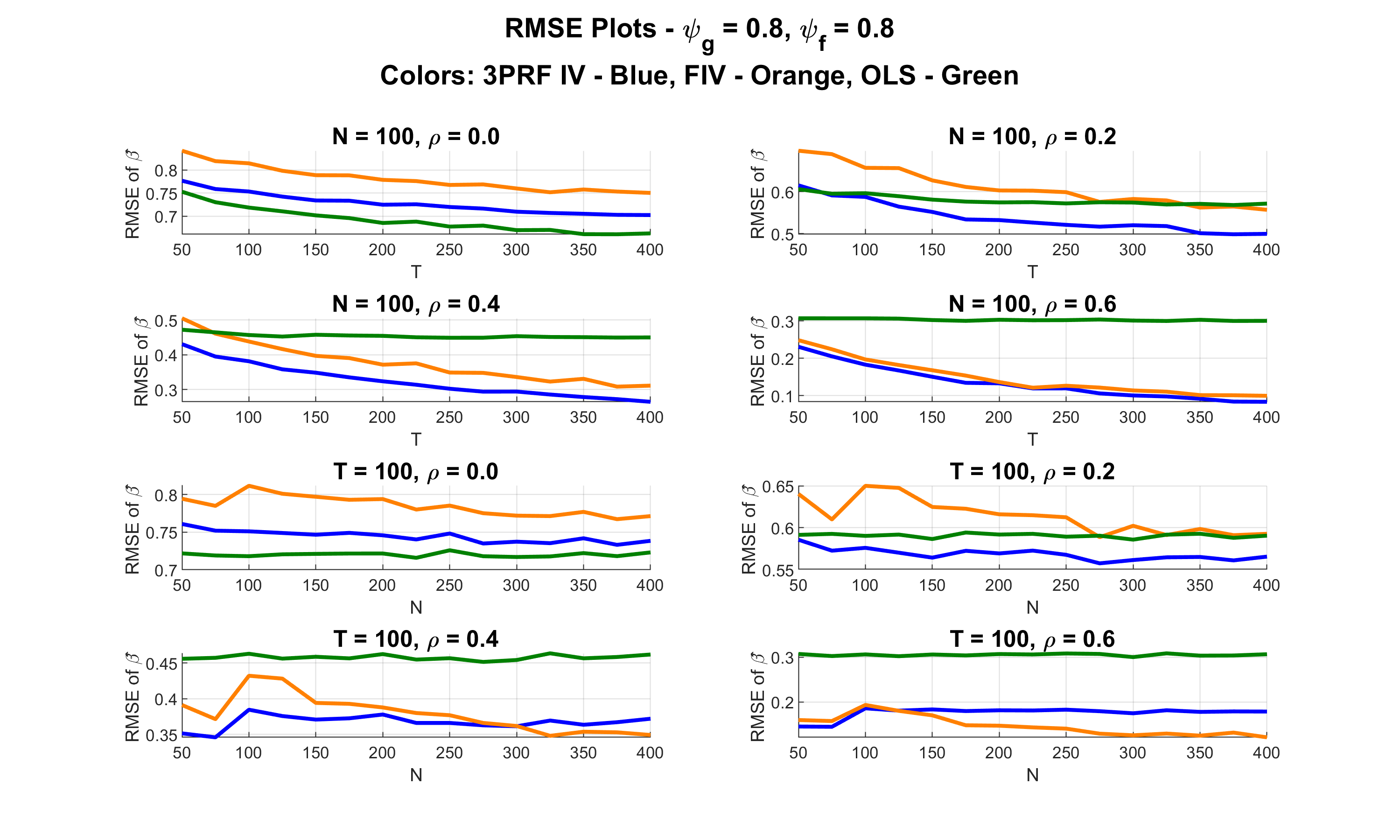
The paper introduces a supervised factor-based IV estimator (3PRF IV) that extracts only the factors relevant for the endogenous regressor, improving efficiency over standard FIV. It establishes conditions for √T-rate asymptotic normality under potentially weak factor structures and shows strong performance in simulations and an empirical application.
[Draft Available on Request]
Abstract
We study the estimation of parameters in a regression model with endogenous regressors, focusing on settings where the endogenous variable is related to a large set of exogenous instru- ments through a small number of unobserved latent factors. We extend the Factor Instrumental Variable (FIV) estimator of Bai & Ng [2010] by introducing supervision into factor estimation: rather than extracting all latent factors using the method of principal components (PC), we apply the Three-Pass Regression Filter (3PRF) to selectively estimate only those factors that are relevant for the endogenous regressor. We refer to this novel estimator as the 3PRF IV estimator. This methodology effectively discards irrelevant factors that could otherwise intro- duce inefficiency into the estimation process. Our framework also accommodates weak factor structures, allowing for the possibility that the factors driving the instruments are weak and that relevant and irrelevant factors may differ in strength. We derive conditions under which asymptotic normality of the structural parameter at a √T rate is attainable. When relevant factors are weak, achieving √T -rate asymptotic normality requires the sample size T to grow sufficiently fast relative to the number of instruments N , with even stricter conditions when irrelevant factors are stronger than relevant ones. Monte Carlo simulations demonstrate strong finite-sample performance of our supervised 3PRF IV estimator. An empirical application esti- mating the New Keynesian Phillips Curve yields coefficient estimates consistent with those in the established literature, thereby validating our approach.
Macro Factors in Bond Risk Premia: Revisited
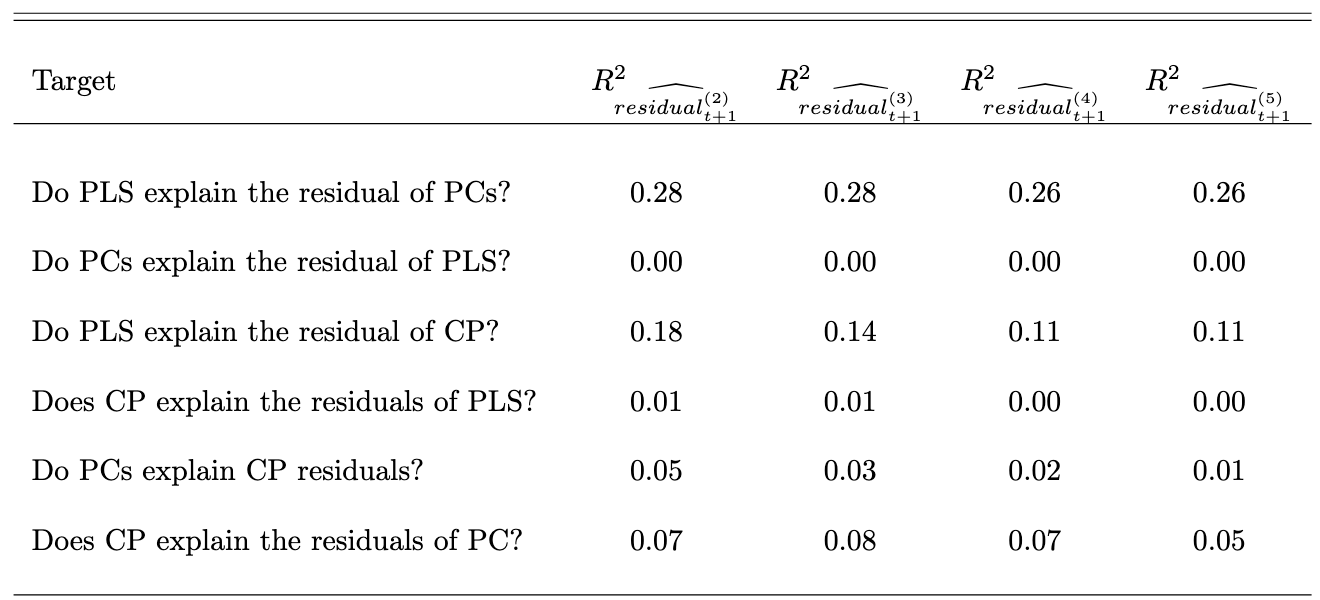
Using improved econometric methods, we reassess the role of macroeconomic variables in explaining bond risk premia and find their importance was previously understated. Once macro-factors are accounted for, forward rates add little explanatory power for bond risk premia—a previously unknown result.
[Draft Available on Request]
Abstract
This paper revisits the role of macroeconomic factors in explaining bond risk premia. We show that carefully constructed supervised macroeconomic factors explain a substantial and economically meaningful share of variationin bond risk premia—far more than previously documented. In contrast, widely used principal component–based macro factors, such as those of Ludvigson and Ng (2009), substantially understate the true explanatory power of macroeconomic information. As a result, the influential conclusion of Cochrane and Piazzesi (2005) that financial factors dominate macroeconomic forces is overturned: once the variation explained by our supervised macro factors is removed, neither financial factors nor PCA-based macro factors explain any remaining variation in bond risk premia, whereas the reverse is not true. These findings imply that standard financial and unsupervised macro factors capture only a subset of the information embedded in macroeconomic fundamentals when they are properly measured.
Presentations in Research Conferences/Seminars
| Oct 2025: The 35th Annual Midwest Econometrics Group Conference | UIUC, IL, USA. |
| Sep 2025: The 2025 California Econometrics Conference | Victoria, BC, Canada |
| Aug 2025: Research seminar at the Indian Institute of Technology Delhi | Delhi, India |
| Aug 2025: The 13th World Congress of the Econometric Society | Seoul, South Korea |
| Apr 2025: Research talk at the Ontario Agricultural College, University of Guelph | Guelph, ON, Canada |
| Apr 2025: Graduate Research Symposium at the University of California, Riverside. | Riverside, CA, USA |
| Jan 2025: Research Seminar at Southern Illinois University, Carbondale | Carbondale, IL, USA |
| Jan 2025: Research Seminar at Gettysburg College | Gettysburg, PA, USA |
| Dec 2024: 19th Annual Conference on Economic Growth and Development at ISI Delhi | Delhi, India |
| Dec 2024: The European Winter Meeting of the Econometric Society (EWMES 2024) | Palma, Spain |
| Nov 2024: 34th Annual Midwest Econometrics Group Conference at Uni. of Kentucky | Lexington, KY, USA |
| Oct 2024: Fall 2024 Econometrics Seminar at UC Riverside | Riverside, CA, USA |
| Sep 2024: The 2024 California Econometric Conference at UC Davis | Davis, CA, USA |
| Oct 2023: Fall 2023 Econometrics Seminar at UC Riverside | Riverside, CA, USA |
| May 2023: Spring 2023 Brown Bag Seminar at UC Riverside | Riverside, CA, USA |
| Feb 2023: Winter 2023 Brown Bag Seminar at UC Riverside | Riverside, CA, USA |
| Dec 2022: Annual Conference by The Econometric Society & Delhi School of Economics | Delhi, India |
| Dec 2019: Annual Conference by the Indian Statistical Institute | Delhi, India |